Control estructural por medio de sensores wireless y cómputo integrado
El origen del tema que escogí para esta entrada es el décimo tercero simposio anual internacional en materiales y estructuras inteligentes. Se llevó acabo en San Diego California en Febrero y Marzo del 2006.
A grandes rasgos el contenido de la publicación trata sobre el campo de la ingeniería estructural (o de estructuras, en específico la ingeniería civil) apoyado por la ingeniería informática-electrónica para la investigación de sensores wireless (todavía no implementados en la ingeniería civil) de bajo costo para su uso en sistemas de monitoreo estructural.
La finalidad de esta investigación e implementación es ahorrarse tanta labor y costos asociados a las instalaciones hechas con largas extensiones de cables coaxiales en los actuales sistemas de control de estructuras, los autores mencionan que esta tecnología es el futuro para los sensores de control de estructuras.
Bien, lo que este sistema propone es que los sensores wireless son diseñados para cumplir 3 tareas principales en el sistema de control:
1 - Los sensores inalámbricos son responsables de la recolección de datos de las respuestas estructurales.
2 - Los sensores inalámbricos son responsables del cálculo de las fuerzas de control.
3 - También son responsables de emitir comandos a los actuadores.
En la publicación se menciona que un prototipo de sistema "Wireless Structural Sensing and Control (WiSSCon)" fue presentado en el simposio.
Y para evaluar el desempeño de este prototipo se llevan acabo experimentos a media escala con 3 estructuras de acero en las que un amortiguador magnetoreológico está instalado. El funcionamiento del sistema de WiSSCon se ha demostrado que es efectivo y fiable.
Los autores y creadores de este sistema dicen que WiSSCon no es más que un prototipo diseñado para estar sensando y retroalimentando de información en "tiempo real" por wireless al sistema de control. También mencionan que la comunicación por wireless es usada para la retroalimentación de la respuesta estructural para así calcular soluciones de control basadas en la información que se envío.
Para que les haga más sentido la transmisión de la información y cálculos realizados con la misma, dejo este gráfico que describe perfectamente el sistema (La imagen fue obtenida de la misma publicación: )
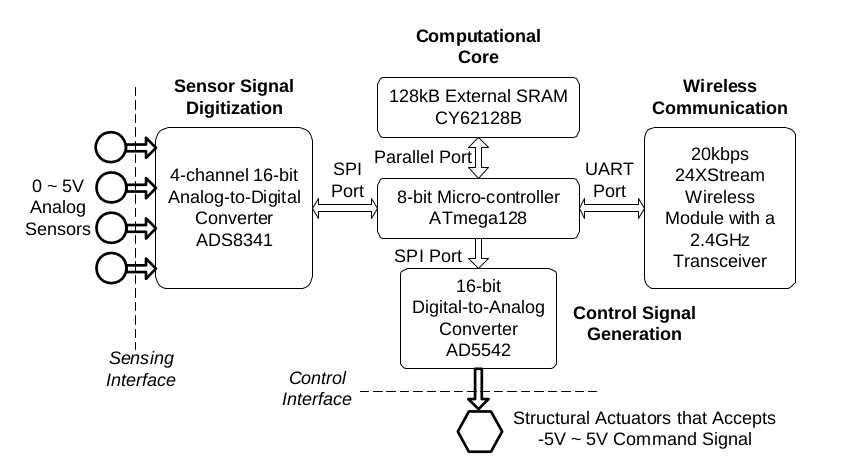
La arquitectura del hardware de la unidad de control por wireless utilizado para este prototipo (WiSSCon) es la siguiente (se puede apreciar la interacción del cómputo embebido):
Y para los que creian que la clase de cómputo integrado no era tan importante, el módulo de control de señales (que se ilustra en la imagen siguiente) está hecho con mictrocontroladores ATmega128 (los usados en las tarjetas Arduino) y amplificadores operacionales, además de convertidores Digital-Analógicos.
Y así se ve en conjunto el módulo de control de la señal conectado al sensor wireless (básicamente es el aparato situado debajo de la estructura en la imagen 1, nótese la antena de emisión/recepción del módulo)
Campos de aplicación y conclusiones
En la ingeniería civil, el mejoramiento a la respuesta (datos del movimiento de estructuras) de estructuras debido a la fuerte excitación dinámica es un reto difícil.
Como ya antes mencioné, el sistema WiSSCon ha demostrado que es efectivo y fiable por lo cual no dudo en la futura aplicación de este y similares sistemas de control en las estructuras civiles.
Las personas que trabajaron en esta investigación son: Yang Wang, Andrew Swartz, Jerome P. Lynch, Kincho H. Law, Kung-Chun Lu, Chin-Hsiung Loh
Y la liga de la publicación es:
Las palabras clave para encontrar la publicación aquí presentada fueron:
Keywords: structural control, wireless communication, embedded computing
La redacción total de este post fue hecha por mí, y todas las imágenes fueron obtenidas de la misma publicación.
PD: La publicación no contenía gran información de los temas tratados en la materia, por tal motivo no puse ecuaciones, técnicas o conceptos estudiados durante el semestre.
Saludos!